Ein Labor kontaktierte uns kürzlich, weil seine nächtliche Datenbankoptimierung nicht mehr lief. SENAITE LIMS lief an der Oberfläche einwandfrei. Nutzer meldeten sich an, registrierten Proben, erfassten Ergebnisse, veröffentlichten Berichte. Nichts in der Oberfläche verriet etwas.
Unter der Haube war die Datenbank monatelang ungebremst gewachsen.
Die geplante Pack-Operation schlug jede Nacht stillschweigend
fehl. Die Ursache stellte sich als ein einziger korrupter
Datenbankdatensatz heraus. Ein abgeschnittenes Objekt, vermutlich
entstanden, als ein Server-Neustart einen aktiven Schreibvorgang
unterbrach. Dieser eine schlechte Datensatz blockierte den
gesamten Garbage-Collection-Prozess und führte dazu, dass das Pack
bei jedem Lauf mit einem EOFError abbrach.
Das Labor erfuhr zufällig davon, drei Monate später, als die Platte 80 % erreichte und ein nicht verwandter Alarm auslöste.
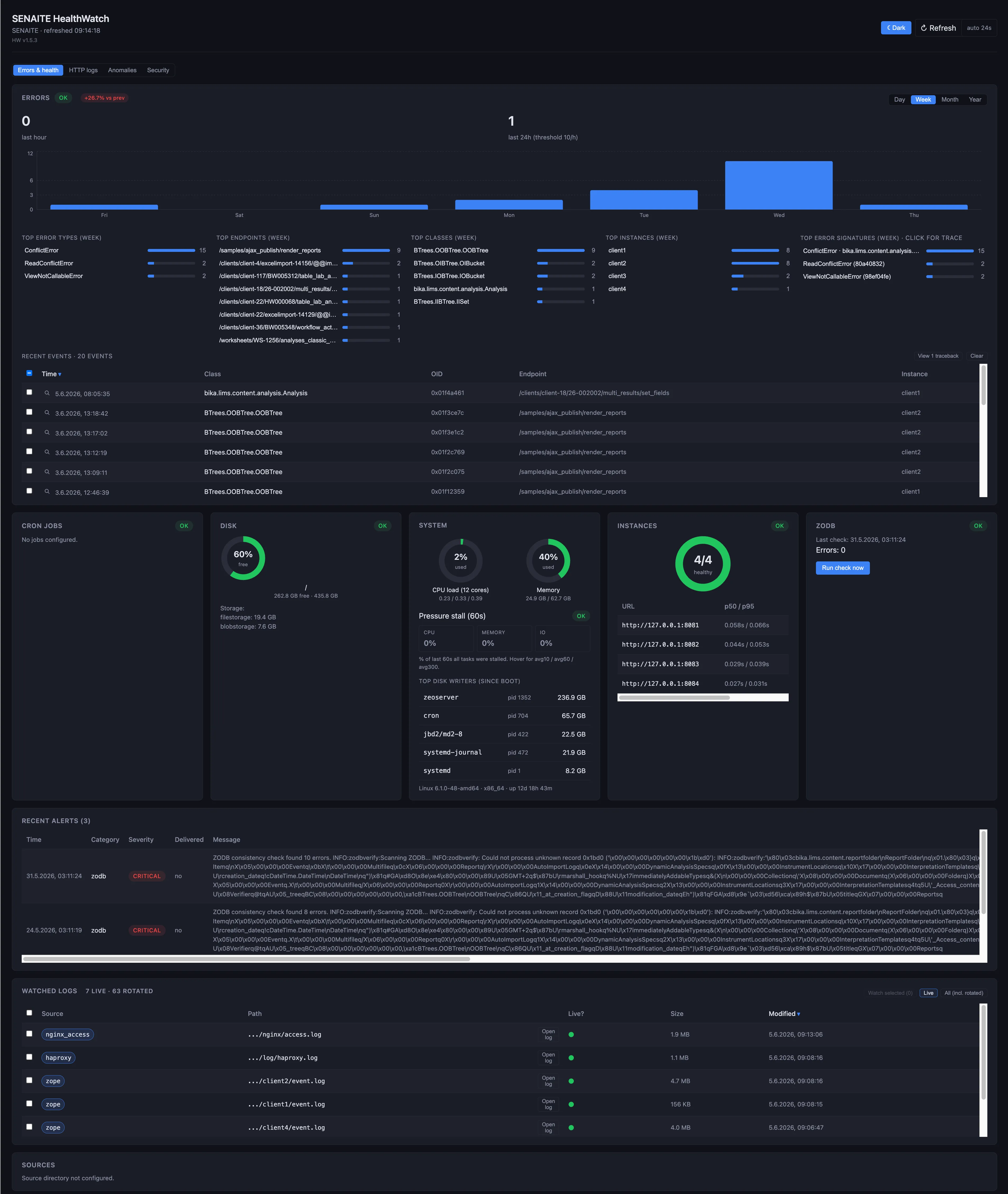
Genau für diese Art von Ausfällen gibt es proaktives Monitoring.
Was proaktives Monitoring tatsächlich bedeutet
Die Versuchung beim Monitoring ist, die Oberfläche zu beobachten: ist der HTTP-Endpoint oben, ist die Platte unter 90 %. Das sagt Ihnen über ein LIMS sehr wenig.
Ein LIMS hält Betriebsdaten in einer ZODB (Zope Object Database), das mit der Zeit wächst, planmäßig kompaktiert wird und von ein paar leisen Operationen abhängt, deren Erfolg niemand sieht, weil niemand hinschaut. Proaktives Monitoring beobachtet diese Operationen:
- Ist das Pack der letzten Nacht gelaufen? Wurde es abgeschlossen?
- Ist das Backup der letzten Nacht gelaufen? Hat die Restore-Verifikation bestanden?
- Gibt es ConflictErrors im Log, die der Nutzer nicht gesehen hat?
- Ist ein Objekt in der Datenbank defekt?
- Verschlechtert sich die Antwortzeit? Beschleunigt sich das Plattenwachstum? Sind die Worker ausgelastet?
Wenn Sie nur prüfen, ob SENAITE auf HTTP antwortet, erfahren Sie von Problemen am Tag, an dem sie einen Ausfall verursachen. Wenn Sie die fünf Fragen oben prüfen, erfahren Sie in der Nacht, in der sie beginnen.
HealthWatch
Wir haben HealthWatch gebaut, weil wir genau das für die Labore brauchten, die wir betreuen. Es läuft als kleiner Python-Dienst auf Ihrem SENAITE-Server, fragt ZODB und SENAITE-Kataloge direkt ab und sendet strukturierte Metriken an unsere zentrale Zabbix-Monitoring-Instanz.
Es überwacht sechs Bereiche.
Datenbankkonsistenz
Vollständige ZODB-Integritätsscans nach Zeitplan. ConflictError-Erkennung im Event-Log. Erkennung abgeschnittener Objekte durch Durchlaufen des Objektbaums und Suche nach solchen, die sich nicht deserialisieren lassen. Genau der Fehlermodus, der den Fall oben verursacht hat, ist das Erste, was es prüft.
Instanzgesundheit
Antwortzeiten am Plone-Frontcontroller. Worker-Verfügbarkeit. Speicherobergrenze pro Worker. Tiefe der Background-Task-Queue. Die Art von Dingen, die schleichend schiefgeht, bei der das Labor nicht bemerkt, wie die Antwortzeit von 200 ms auf 4 s kriecht, bis die Nutzer die IT-Leitung anschreiben.
Die HTTP-Logs-Ansicht verfolgt das haproxy-Access-Log und das nginx-Error-Log, klassifiziert jede Anfrage nach Status-Familie und zeichnet den Sieben-Tage-Trend, sodass ein plötzlicher Anstieg der 5xx-Antworten als grüner Balken auftaucht, den jeder sieht. Quellen, Top-Pfade und die letzten Fehlerantworten stehen daneben, damit Sie einer Regression nachgehen können, ohne das Dashboard zu verlassen.
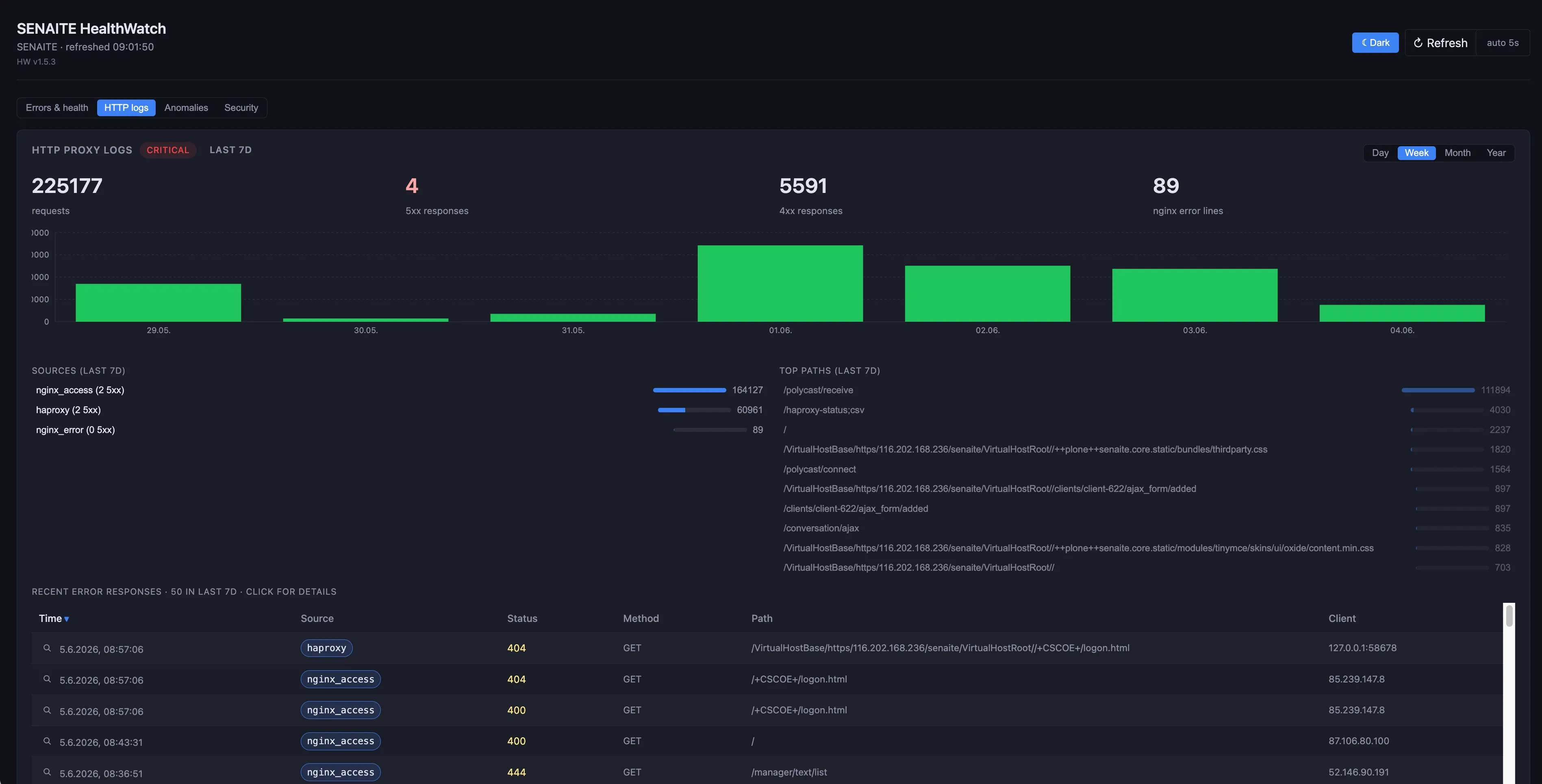
Speicher
Wachstumsrate der Data.fs. Freier Plattenplatz. Größe des Backup-Ziels. Pack-Verhältnis (wie viel Speicher ein Pack tatsächlich zurückgewinnt, was Ihnen sagt, ob das Pack seine Aufgabe erfüllt).
Geplante Tasks
ZODB-Pack, automatisiertes Backup, Cron-Jobs, von denen das Labor abhängt. Jeder meldet bei Abschluss Erfolg oder Fehler. Wenn ein geplanter Task stillschweigend aufhört zu laufen, bemerkt es HealthWatch im nächsten erwarteten Fenster.
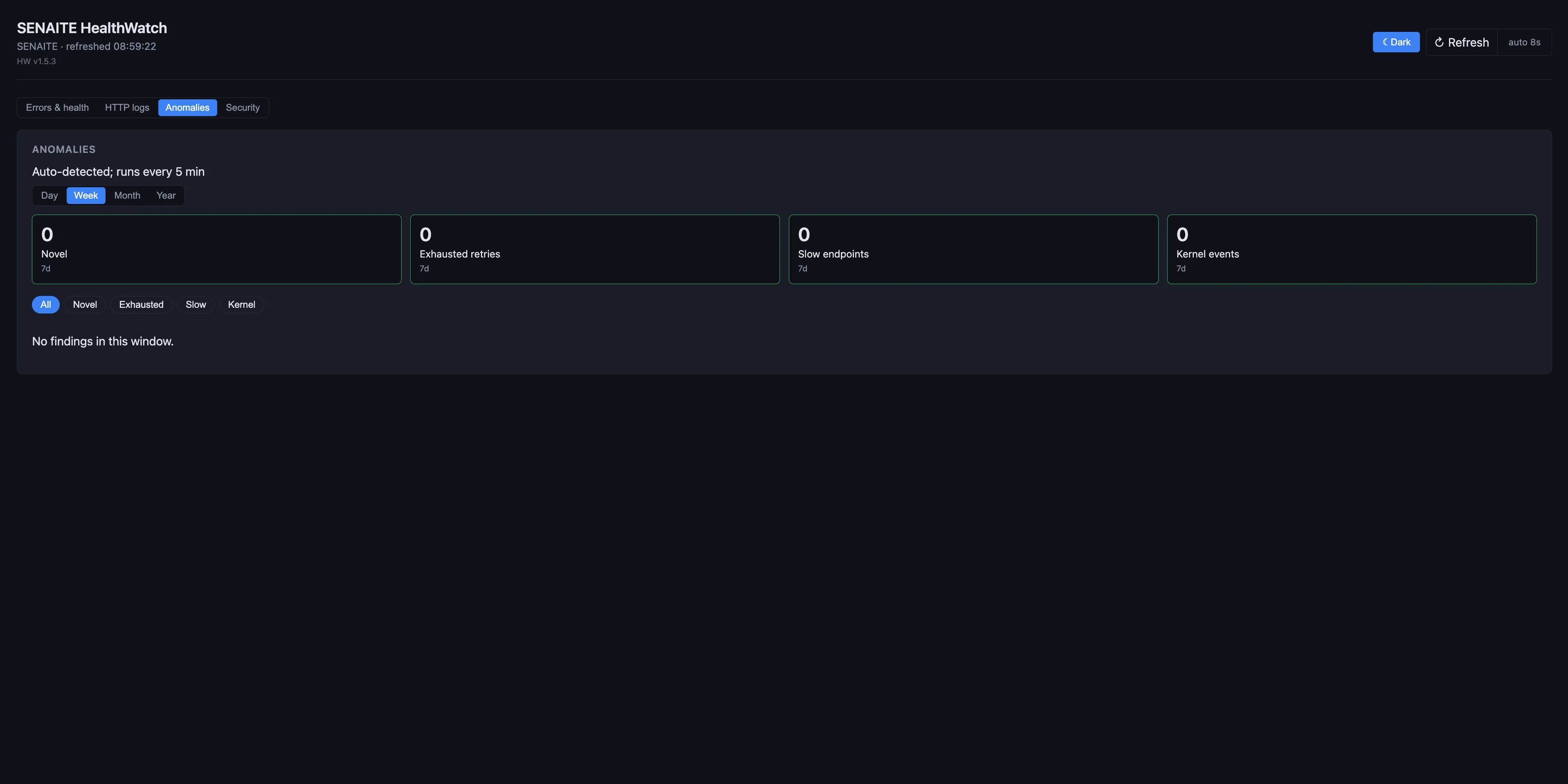
Auffälligkeiten
Verhalten, das technisch korrekt, aber statistisch ungewöhnlich ist: Endpoints, deren Antwortzeit driftet, ein Worker, der denselben Task bis zur Erschöpfung wiederholt, Kernel-Events, die plötzlich auf einer Node auftauchen, auf der sie zuvor nie geloggt wurden, oder neuartige Fehlersignaturen, die in diesem Codebestand noch nicht gesehen wurden. Der Anomalies-Tab gruppiert sie nach Kategorie (Novel, Exhausted retries, Slow endpoints, Kernel events) und rollt sie über das konfigurierte Fenster zusammen, sodass Sie heute gegen die letzten sieben Tage auf einen Blick vergleichen können.
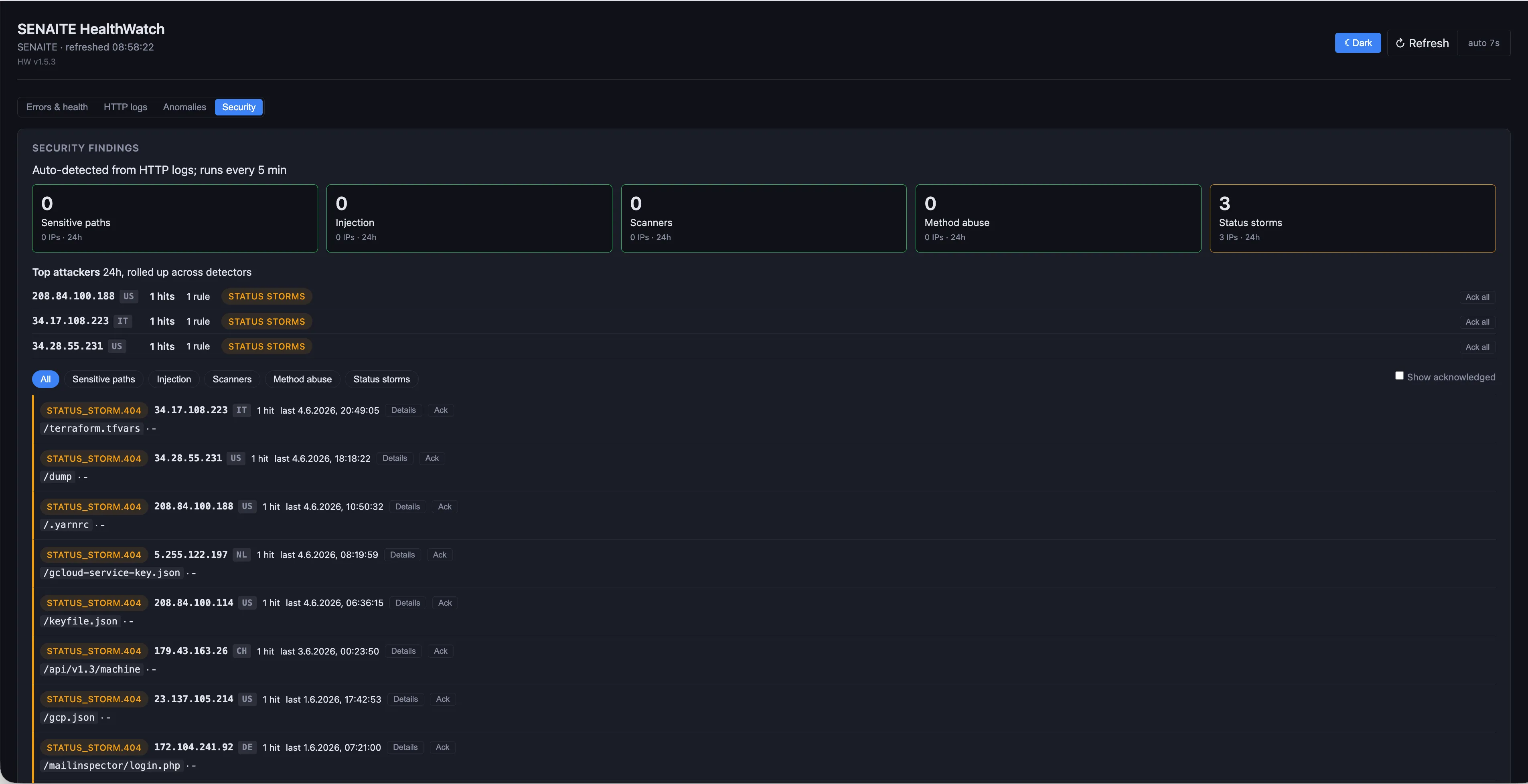
Sicherheit
Throttling fehlgeschlagener Logins, auffällige Anfragemuster, Status-Code-Stürme auf Pfade, die nicht existieren sollten. Der Sicherheits-Tab von HealthWatch aggregiert das laufende HTTP-Log in einem Fünf-Minuten-Fenster, klassifiziert jede Auffälligkeit nach Kategorie (sensible Pfade, Injection-Versuche, Scanner, Method Abuse, Status-Stürme) und zeigt die obersten Angreifer, sobald eine Schwelle anschlägt.
Was passiert, wenn etwas ausgelöst wird
HealthWatch-Alarme werden an unsere zentrale Zabbix-Instanz weitergeleitet. Alarme außerhalb der Geschäftszeiten gehen an unsere Rufbereitschaft. In den Geschäftszeiten gehen sie an das Team, das den Vertrag dieses Labors betreut.
Für Professional- und Enterprise-Kunden zeigt ein kundenseitiges Web-Dashboard dieselben Daten, sodass das IT-Team des Labors sieht, was wir sehen. Enterprise-Kunden erhalten wöchentlich einen Gesundheitsbericht per E-Mail.
Ein Klick auf ein Event öffnet eine Seitenleiste mit dem vollständigen Kontext: Klasse, betroffene OID, Endpoint, Instanz, die es ausgelöst hat, Pfad der Quelldatei, Nachricht und der vollständige Python-Traceback. Nachricht und Traceback sind je einen Klick vom Clipboard entfernt, sodass der diensthabende Ingenieur einen exakten Auszug ins Ticket einfügen kann, ohne Logdateien grepen zu müssen.
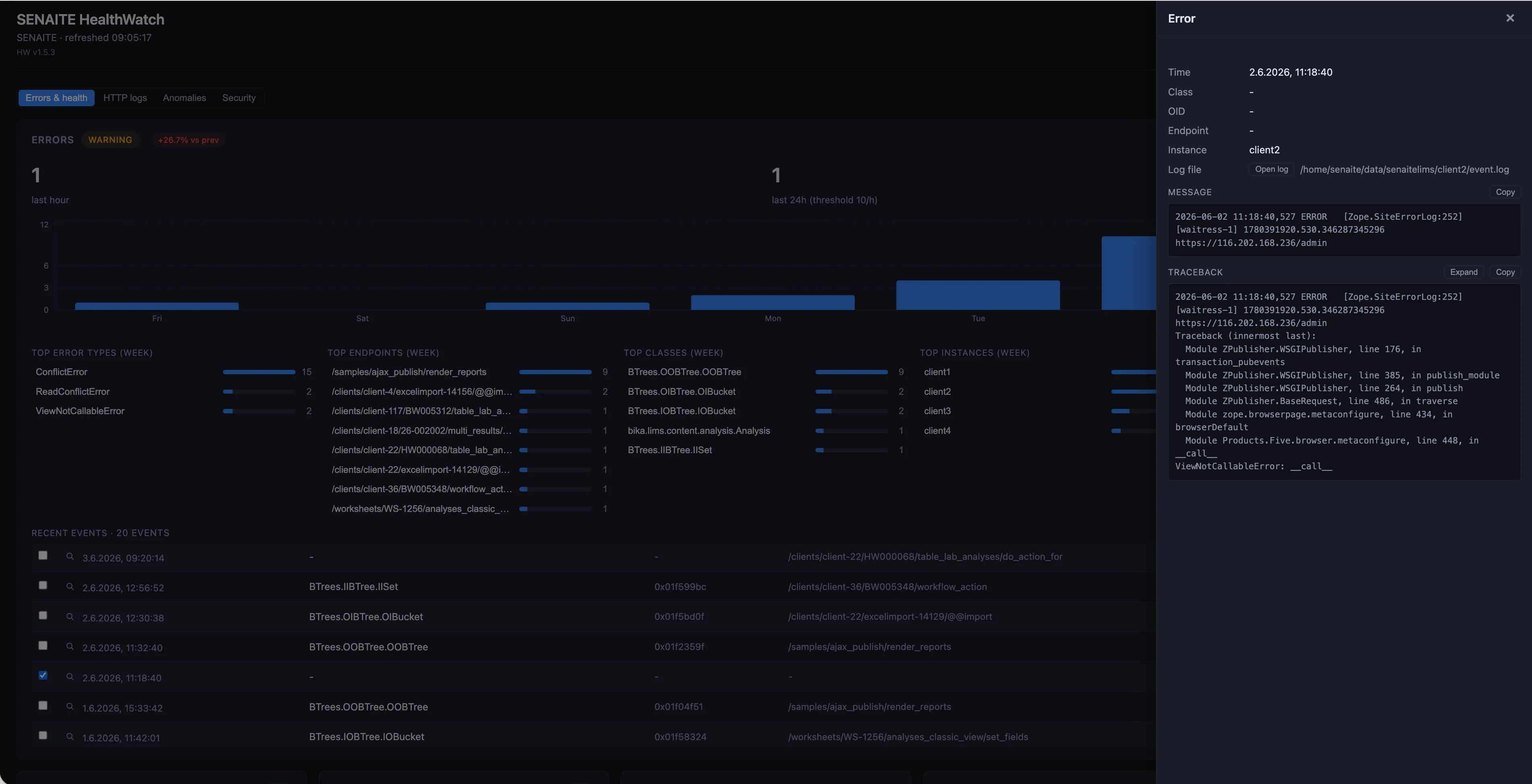
Zurück zum Fall
Für das Labor in der Geschichte oben war die Behebung unkompliziert, sobald wir wussten, worauf wir schauten. Wir identifizierten das abgeschnittene Objekt über einen ZODB- Durchlauf, reparierten die Referenz, und das nächste Pack lief sauber. Die Data.fs sank über Nacht von 8,4 GB zurück auf 2,1 GB. Kein Datenverlust.
Weniger akzeptabel waren die Monate Wachstum, bevor jemand etwas bemerkte. Hätte HealthWatch auf diesem Server gelaufen, hätten wir das erste fehlgeschlagene Pack am Morgen nach dem Fehlschlag erwischt. Das ist der ganze Punkt.
Was das kostet
Jeder SENAITE Care-Tarif enthält HealthWatch. Der Essential-Tarif beginnt bei EUR 300 pro Monat und deckt Monitoring, planmäßige Wartung und E-Mail-Support ab. Für die meisten Labore, die SENAITE in Produktion betreiben, ist das die richtige Untergrenze.
Wenn Sie wissen möchten, was wir auf Ihrer Installation sähen, melden Sie sich. Wir können einmalig ein Gesundheitsaudit durchführen, ohne dass Sie sich zu einem Tarif verpflichten.
Was Sie diese Woche tun sollten
Ob Sie HealthWatch nutzen oder nicht, drei Prüfungen, die diese Woche auf Ihrem SENAITE lohnen:
- Das Event-Log auf den String
EOFErrorprüfen. Wenn Sie ihn sehen, schlägt Ihr Pack wahrscheinlich fehl. du -shauf Ihre Data.fs heute mit dem Wert vor drei Monaten vergleichen. Ein Pack, das läuft, verkleinert sie. Wenn die Zahl nur wächst, läuft Ihr Pack nicht.- Einen Restore auf einem aktuellen Backup versuchen. Finden Sie jetzt heraus, ob das Backup wiederherstellbar ist, nicht an dem Tag, an dem Sie es brauchen.
Die ersten zwei dauern je eine Minute. Die dritte dauert eine Stunde und ist der Unterschied zwischen einem wiederherstellbaren und einem verlorenen Labor.
